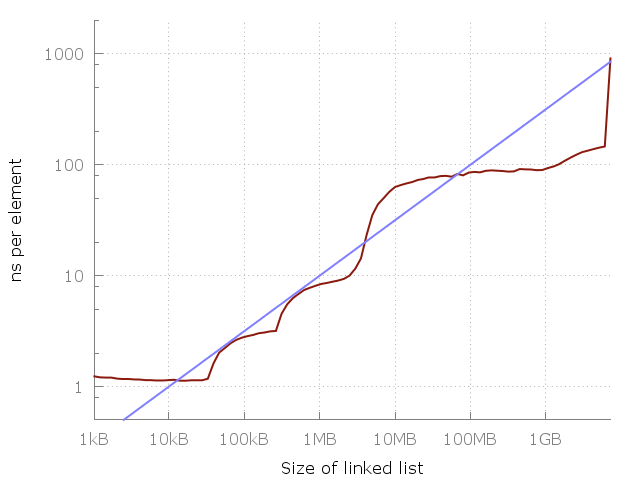
> We can ask a question: how long (in nanoseconds) does it take to access a type of memory of which an average laptop has N bytes? Here's GPT's answer:
"Here's what GPT says" is not an empirical argument. If you can't do better than that (run a benchmark, cite some literature), why should I bother to read what you wrote?
Thanks for the good links. I think we generally have become so accustomed to the scaled up von Neumann strategy that we don´t see how much efficiency and performance we leave on the table by not building much smaller memory hierarchies.
Maybe when google actually did searches. A coworker today was unable to find a very straightforward quoted text on google, on duckduckgo the first few hits were exactly what we were looking for.
Why would it not run with your provided hypothesis? It even added an explicit hint that this is a hypothetical scaling exercise, and that real hardware does not scale like that.
But generally, sure, you can make LLMs say many false things, sometimes even by just asking them a question in good faith, and it certainly casts some doubt on a blog post quoting an LLM as a source.
{kind=link}
> We can ask a question: how long (in nanoseconds) does it take to access a type of memory of which an average laptop has N bytes? Here's GPT's answer:
"Here's what GPT says" is not an empirical argument. If you can't do better than that (run a benchmark, cite some literature), why should I bother to read what you wrote?