I think the software decoding technique used here is incomplete.
Consider what would happen if a data sector contained 12 * 0x00, 3 * 0xA1, 0xFE, ... then this implementation could mis-sync. On real hardware you'd have to be even more unlucky to have the CRC match -- which also isn't checked in this implementation. Using this as-is on real floppies could result in reading corrupt data. It would be possible to construct a floppy that would read correctly on real hardware and sometimes mis-read data with the current SW implementation.
The problem is that the 0xA1 bytes on the disk are special. The 0xA1 bytes are MFM encoded with a missing clock pulse -- making them "0xA1 syncs" that don't match an 0xA1 data byte.
This is what I think dragontamer is alluding to in another thread -- you cannot properly decode the header unless you also recognize the missing clock pulse. So it is important to do the clock recovery in order to notice this.
The special encoding is also present for 5.25 and early hard drives using MFM encodings.
> Fun fact! floppy disks actually contain a lot more surface area than 1.44mb. By my calculation, you'll get closer to 1.70mb but a lot of that extra space is earmarked for synchronization barriers and sector / track metadata.
This explains the 2M utility that allowed storing about 1.8mb on a floppy disk. It was fun playing with it.
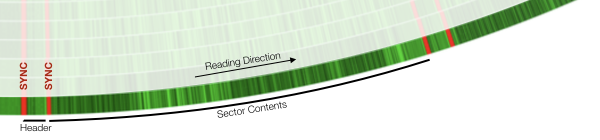
I think this is a case where a picture is worth a thousand words. This excellent article "Visualizing Commodore 1541 Disk Contents" [1] by Michael Steil about the Commodore 64 disk format, includes visualizations of the magnetic flux as stored on disk.
This bit is particularly relevant: https://www.pagetable.com/docs/visualize_1541/sector.png See the solid bit at the end of the sector, just before the next header? You could squeeze a few more bytes in there, but if the drive motor is just slightly too fast, it'll overwrite the next sector. That's why there's a gap, tolerance for timing variation.
Most floppy drive technologies wrote blindly, guessing where they were on the disk based on timing estimates since the controller last saw a sector header. This is also why disks needed to be "formatted". Not just in the sense of writing the file system data structures, but writing out all the sector headers. This had to be done all at once with the same drive, due to those small timing variations.
I recall it was also not unheard of to have floppy drives that could be incompatible with each other. A drive that was a tad slow might format a disk that would work for itself, and other drive, but that disk might not work in a drive that was a tad too fast (and vice-versa). This wasn't common, just frequently enough to occur so occasionally as to always be baffling, particularly in an office with lots of PCs.
At high school (in the 1.44mb / w95 era) I encountered a floppy disk that had literally two different filesystems on it depending on what machine you read it in. Not entirely sure how that worked. One machine showed one filesystem, the rest showed another.
I guess the alignment on that one particular drive must have been ridiculously far off baseline.
Amiga had floppy drives that could read/write 1.76MB on HD disks and 880K on SD floppys. I think this was possible because they could control the speed.
The only HD drive ever available for Amiga was sold with some 4000 units - a modded Chinon FZ357A spinning at half rpm because nobody at commodore knew how to update PLL circuit in Denise. 1.76MB capacity was reached by not using standard PC format.
Paula being the only chip that had absolutely zero changes from the Amiga 1000 to the 4000. That fact alone is a sad example of Commodore's mismanagement of the platform. Well, except for the CIA which traces its lineage even further back to the C64.
Specifically, AmigaOS's floppies write one sector after another, with a single gap in the entire track.
Whereas the IBM PC format has a gap in each sector. This is because RAM was more expensive back then, thus holding an entire track in memory would have an associated cost.
> Whereas the IBM PC format has a gap in each sector. This is because RAM was more expensive back then, thus holding an entire track in memory would have an associated cost.
A major factor - I'd argue even more significant than cost of memory - was that the IBM PC used an off-the-shelf floppy disk controller chip (NEC uPDC765A), which was hardwired to support the industry-standard IBM floppy track format (which had evolved from IBM's 3740 mainframe data entry system, introduced in 1973), and didn't support the Amiga's custom track format. Whereas, the Amiga could do this because it didn't actually have a floppy disk controller-the functionality of controlling floppy disks was in part contained in their custom ASICs, and in part implemented in software by the CPU. Unlike the Amiga, the original IBM PC eschewed proprietary ASICs in favour of off-the-shelf chips, in order to minimise time-to-market.
True, they use these pre-existing standard controllers. But these standard controllers and the track format were indeed designed in that way due to the ram limitation.
Ironically, it is possible to read arbitrary formats with the debug read track operation. Yet, it needs to find one triple sync word somewhere in the track; a controller limitation.
Unfortunately, the Amiga standard track format didn't account for that, and uses the same sync word (the 4489 one) but double.
It could have been designed to use a different sync word, and include a triple 4489 at the track start, but they didn't think about it at the time.
Some tricks bit-banging the controller allow for writing arbitrary tracks.
It is also possible to read arbitrary tracks, if there's two floppy drives and a standard ibm pc formatted disk is present in the other one, by switching the drive after the controller has started reading.
> But these standard controllers and the track format were indeed designed in that way due to the ram limitation.
The track format was designed that way in the early 1970s. RAM was likely one reason for it, but another was that the 3740 used sector gaps as record boundaries; it was commonly configured so each 128 byte disk sector held a single 80-column punch card worth of data. 3740 format floppies support deleting sectors (by using a different sync word in the sector header) so you could delete database records. PC floppy controllers supported deleted sectors too, even though almost no software used them (some copy protection schemes did, but duplicating deleted sectors isn’t hard once you know they exist.) Part of the motivation for 128 byte sectors was likely the fact that it was the smallest power of 2 that could fit a whole punch card.
Also, a whole 3740 track was 3338 bytes (26 sectors of 128 bytes), which was a lot of RAM in 1973; in 1981, a whole PC floppy track was 4096 bytes. 4KB was a lot less expensive in 1981 than in 1973, so by then it would have been less of a motivating factor than when the track format was initially defined.
Thanks to the pluggable device layer, you could push that to 984kB or 1968kB with diskspare¹. The incredible thing, IMO, is that the implementation is only 5kB(seven times smaller than the formatted English docs).
Just the absolute worst drives ever released to the public, but it was that or tapes and while most will agree that the 1541 was a slow FDD, waiting 30+ mins to load a tape (don't forget to flip it) was much worse.
Then copy protection companies decided that the very best way to CP software was to create unreadable/unwritable sectors and let the drive slam the head against the arrester trying to read it, because they didn't have to replace the drive. That was a you problem.
I don't think I ever got a stable disk above 1.6MB. Which was just enough for a few things but generally not worth it.
The motors in the disk drives could be controlled directly, and you could pack the tracks tighter by stepping the motor just a little bit less than you were supposed to. And in theory if you did it right, other disk drives could read it.
'In theory' is carrying a lot there. I tended to find 1.5something to 1.6something worked and anything higher rarely ever did.
Could you really step less than a standard track? I would have assumed that the stepper motor's steps are track aligned, so either you step, or you don't...
"There are 80 tracks on your average 3.5" floppy drive. You can select a given track by pulsing the STEP pin and combining it with the direction select pin."
Microsoft was able to distribute Windows 95 in fewer floppies by creating their own floppy disk format called DMF that used utilized more sectors per track.
IBM did something similar ...I want to say with OS/2 but that can't be right (or I'd have more issues with it under emulation than I have). Maybe with PC-DOS 2000?
One of my first jobs in the early 90's was to write a device driver for a floppy disk drive in an embedded system. There was the drive itself, the floppy disk controller chip, and the direct memory access (DMA) chip. I only had the specs for the latter two in English.
Analysing the circuits, I saw the controller chip was wired such that use of the DMA chip was software configurable, so I thought beaut, I'll write and test the first iteration without DMA, then add and test that after.
Couldn't get it working. Scratched my head for a while until, while discussing it with one of the hardware engineers, was told that while the controller chip had been wired software configurable, the floppy drive itself was hard-wired to use DMA. If only I had the spec for that I would have figured it out!
What kind of floppy drive was this? PC and just about every floppy drive I've ever seen only has motor, step, read / write data etc signals and no concept of DMA etc which would solely be handled by the FDC itself
It looks like a fairly standard floppy drive. I might be misremembering or misinterpreted the particulars due to neither me and the hardware guy being able to speak the other's native tongue that well, but the upshot was despite what the circuit told me about the configurability of the controller chip, it was not going to work without DMA.
The linked article shows the "standard" pinout for a 3.5" floppy drive, and it's clear the interface is below the level of anything like DMA.
I assume even if you were using something that looked like a standard floppy drive, it was using a higher level interface, or was including something like the controller ISA board in the "interface".
Interesting and fun project! I found the MFM encoding page particularly enlightening as it explained why you have to write a full sector at a time on a floppy, even though there's nothing physically constraining you to that so far as I could see on the electromechanical/hardware side of things.
And on that page the "make sure the compiler didn't inject 10,000 lines of boundary checks" bit told me everything I needed to know about what language the project was written in :lol: - here's the link to the driver: https://github.com/SharpCoder/floppy-driver-rs
(Side note: I'm glad to see the Teensy continuing to get love; I adopted it back when it was at v1 and v2 as it was just such a complete no-brainer of a better choice than the Arduino stack everyone was using back then. I think now there's even an Arduino-on-Teensy software stack, but I've moved to just using STM32 directly even for just fun home hacks and have greatly enjoyed coding for that target in rust.)
There is also Arduino on Raspberry Pi. The Arduino IDE is a bit annoying but the compatibility between platforms is really nice to see and makes a lot of boards a drop-in replacement for each other if you run out of a particular resource or need some other capability.
I've run some tests and FastLED works well enough to drive matrix displays.
Note that you don't have to run Linux, you can just stick to the Arduino eco-system, which is far more limited than what a full Linux environment would offer you, the Pi Pico is cheap for what it does and gives you an option with lots of memory in the footprint of the smaller Arduino's.
Fun fact! While I was developing my driver, I ruined many entire tracks by leaving this open for too long.
The write gate basically turns on the electromagnet in the head, which will do exactly what you'd expect that to. Early floppy drives' documentation actually came with schematics which show this more clearly.
Early hard drives based on ST-506 also have a very similar interface.
Interesting how author switches to assembly language for more precise reading, but keeps the "read_data" method as a separate non-assembly function. That introduces lots of branching in the code which is busy-loop-based and branch prediction is not what I'd want for consistent timing. It also introduces un-needed dependency: what if the next version of compiler changes the code? All timings (which are based on cycle-counting) will be off.
That said, Teensy 4.0 is 600 MHz ARM cpu, so there are 1000 cycles even between the shortest transitions.. some overhead is fine, the project is not exactly cpu-starved.
I also wonder if author has considered using a peripherals for precise signal capture? Something like timer in capture mode feeding into DMA buffer would allow hardware signal capture with very high precision and without any dependencies on exact instructions emitted.
It would be a good match for some kind of input capture peripheral (the MCU does not have input capture per-se but it is an Cortex M7 so you can certainly build that out of interrupt matrix and some clever configuration of DMA engine) or for abusing SPI USRT if it can support such extremely long frames (which it probably can).
I think judging by the title and the mention of bit banging, the aim of this isn't to get a robust reliable thing going on. I find hacking things together like this to be really fun and doesn't feel like a job. sort of entertainment. but that's just me perhaps.
So do I, but that's more of the reason to keep things robust, no?
In my work projects, I can use the dangerous code like this - because we have compilers and libraries frozen, unit and integration tests, a complex testing process. We can do all the right efforts to ensure the things work, even if solution is intrinsically unreliable.
In my personal projects I write some stuff and start using it, the testing is minimal, and toolchain versions is "whatever platformio decided to pull up today". I'd hate for my project to break just because I rebuilt it to add the new feature and meanwhile my compiler got upgraded. So I'd definitely abuse SPI port or something to get things reliable.
> That introduces lots of branching in the code which is busy-loop-based and branch prediction is not what I'd want for consistent timing.
I don't see how so basic a call would create conditional branches that would have to be predicted. Calling the function is an unconditional branch-and-link, after which it should just be doing a load and returning. (It's LLVM with the equivalent of -O2, it's not going to be doing anything weird.) Unless the return address isn't cached in these processors?
"transition" is signal changing, from high to low or from low to high.
As described in the page, there are multiple signals changing when operating floppy ("track 0", "write gate", "data", etc..). Of them the fastest one is "data", so that's what I am going to focus on.
The 2nd page of writeup [0] says:
A short transition (S) will nominally have 2us between bits, and represents 0b10
A medium transition (M) will nominally have 3us between bits, and represents 0b100
A long transition (L) will nominally have 4us between bits, and represents 0b1000
So we are looking at 3, 4 or 5 microseconds between bits. To get this in CPU cycles, you multiply this by clock frequency - google can help you with units, searching for "2 microseconds * 600 megahertz" [1] shows the answer, 1200, right away. I've rounded this down to 1000, as there are two transitions per pulse and it is all very approximate anyway.
And then you use your embedded knowledge to assign meaning to the number: the CPU is ARM, so 1 instruction/cycle is a good approximation (it could be more due to dual-issue or less due to jumps). So you have like 1000 instructions. Each function call in language like C or C++ might be a 5-20 instructions overhead, and you probably want to read that pin at least 10 times to detect both transitions. The tightest loop is also going to be a dozen instructions or less (read gpio, mask, compare, maybe jump out, increase, compare timeout, loop)
So.. you can do it in C/C++ easily if your main loop involves no function calls (and you have no interrupts). If you use functions to read, your timing is going to be tight and those functions are better be super-optimized, you will be asking your compiler for a lot. Higher level languages like lua/micropython are out of the question (at least for that loop). And as I learned from reading this, rust is also out of the question, although I wonder if there are some unsafe primitives which do not do any checking.
(and yes, there are transistors changing in the background all the time throughout the process, but I really don't care much about them, they are on too low of the abstraction level)
> And then you use your embedded knowledge to assign meaning to the number: the CPU is ARM, so 1 instruction/cycle is a good approximation (it could be more due to dual-issue or less due to jumps). So you have like 1000 instructions. Each function call in language like C or C++ might be a 5-20 instructions overhead, and you probably want to read that pin at least 10 times to detect both transitions. The tightest loop is also going to be a dozen instructions or less (read gpio, mask, compare, maybe jump out, increase, compare timeout, loop)
Nit: That's definitely the wrong approach though IMO.
So you want to accomplish two things:
1. Clock recovery -- Figuring out the timing of a signal
2. Decoding -- Figuring out what that signal means
These are two separate steps and should be done separately, be it in code or hardware. Though advanced protocols combine both into a single step, the older protocols (UART / Floppy / etc. etc.) had these two concepts separated into two different steps.
You won't have 2us between bits: but instead 2.01us or 1.99us between bits, etc. etc. Clock-recovery mechanisms means that even in the face of worst-case timing differences, your code remains resilient.
Decoding is the step you've done here, but it should be done after clock-recovery.
-------------
Traditional clock recovery methods are phase-locked-loops (in hardware), or various XOR-loops (in software) to try and figure out the timing of the clock from the 0-1 and 1-0 transitions.
----
The traditional UART (ex: 9600 baud or 115200 baud) is ~16-ticks per bit. (IE: a 9600 baud UART needs to look at the signal 153600 times per second. A 115200 baud UART needs to look at the signal 1843200 times per second). The 16-times per bit helps you "center your aim" for the transition. You then typically aim at the center-3 timeslots (ex: count number 7, 8, and 9) for when to send and/or read the signal.
--------
That being said, your analysis for "how many instructions you have per timeslice to read the data" is correct. I just feel like adding that the clock-recovery portion needs to be definitely addressed.
The idea there is that if you measure the timing between transitions precisely enough you do not have to do a real clock recovery. The FDD motors seem to be precise and stable enough (after some spin-up time) that this approach works and IIRC even many HW FDCs do something similar internally. But at the same time the low-level format is clearly designed to make some kind of PLL-based clock recovery scheme possible.
After all that is what the FM in MFM implies. There is an obvious parallel with the simplest approach to demodulating FSK (or for that matter DTMF) in digital domain, which works by counting/timing zero transitions of the signal.
The UART receivers are similar in that there is no clock recovery, with the assumption that the clock is stable enough that any kind of frequency error or drift will be insignificant for the relatively short (usually 10bit) frame. The oversampling is there to align the sample point with middle of the symbol and the majority voting from multiple samples serves to average out effects of spiky noise that may be superimposed on the signal.
Pretty much all UART receivers I know of perform either 16x or 8x sampling to figure out where the start and end of bit-transitions are located. This is the clock-recovery mechanism.
You need to discover the edges of the clock, and make sure you read _AWAY_ from those edges. The bits are not well defined on the clock edges. Even with a 100% accurate clock, if you're reading on the edges you'll be very unreliable.
UARTs aim to read on the "center" of bits. (If there are 16x reads per bit, then the "center" is on reads 7, 8, and 9). You'll want to stay away from reading on timeslot#1 or timeslot#16.
For UART this is only about sampling away from the edges. The UART waveform does not have any feature that is usable for clock recovery, the only thing in there is that the start bit (ie. Mark) delineates the start of the frame, how many of the same bits there are is part of the payload. And the stop bit is there so that there is always a transition at the leading edge of the frame. You can do baud rate autodetection, but that is different concept than clock recovery and mostly doable in pure software (well, it is doable by Mk. 1 Eyeball, as the wrong baudrate produces somewhat obvious results).
Obviously there is a bit of history and the whole system was originally implemented electro-mechanically, which is the reason for things like two or more stopbits (it creates time for the mechanism to settle to the reset state) or even the concept of NUL character.
> the only thing in there is that the start bit (ie. Mark) delineates the start of the frame
Well yeah.
It's still clock recovery though and the algorithm to find that edge is the same as clock recovery algorithms in general (lastVal XOR thisVal) to find that edge. All decisions by the UART receiver are based on what happens on that edge.
Lets take a proper encoding scheme, like 8b/10b encoding. The difference is that while UART has 1x opportunity per frame, 8b/10b has multiple opportunities per frame (worst-case 111110 or 000001 as longest string of 0s or 1s) to recover the clock.
Yeah yeah, DC Balance and other such niceties. But from the decoding perspective / hardware+software that decodes the data perspective, 8b/10b is just finding the edges and trying to read from the middle again. Just faster, tighter-tolerances and other benefits compared to the braindead easy/simple UART (but with less... good... clock recovery built in).
Chuck Peddle of 6502 fame did a PC in the eighties called Victor 9000 https://en.wikipedia.org/wiki/Sirius_Systems_Technology#Vict... where he implemented special software driven (6502 controller just like in Commodore drives) ZCLV/GCR floppy drives. 1.2 MB using ordinary 5.25 DSDD disks (500/360 KB capacity in PC). 100% capacity gain from switching to 80 tracks, another 50% on top of that due to ZCLV/GCR. Standard PC 1440KB 3.5 inch HD floppy using same strategy would start at 2160KB.
Whats crazy to me is learning early HDDs didnt use ZBR either, manufacturers were leaving 50% capacity gain on the floor. 1989 Seagate ST157a is comparable to HD floppy, denser tracks at 650 vs 135 tpi, but almost two times lower Bit density :o 10000 vs 17434 bpi. ST157a could lose one platter, or gain half capacity 40->60MB by going with a little bit more complicated ZBR controller (switching bitrate per track).
Take a look at the Greaseweazle https://github.com/keirf/greaseweazle to see what a really high-end solution in this space looks like. It's intended as a from scratch alternative to the better-known KryoFlux.
The Greaseweazle V4, using the FluxEngine GUI, allowed me to capture 1,900 Amiga 880K disks in a row. Each disk took 50 seconds under ideal conditions. I absolutely recommend both for homogeneous collections of disks.
Most of the effort was in entering the text of the labels manually or restarting and switching between capture formats when a Mac or IBM disk cropped up. FluxEngine uses the expected format to decide whether the track most recently read contains errors; and if so, re-read the track 3-5 times, quintupling overall read-times.
All that's needed now is a floppy handling robot, a macro for recording the physical disk and label descriptions, and maybe a container format for all the capture products; thumbnails, cover art, metadata, flux images; that emulators and disk utilities can read, and that the community can re-distribute easily.
Nice, you should consider uploading these dumps to the Internet Archive so that they can be preserved for the foreseeable future. (Of course, that is unless they're strictly private data that was never made available, even unofficially.)
Upvote for greaseweazle (software and physical hardware). Also, the retro option is the Copy II PC Deluxe Option board when used with Copy II PC Deluxe.
Once the drive is spinning that doesn't matter though. Floppies are slow by modern standards mostly because you only get a new (decoded) bit around every 2nd (or for DD drives 4th) microsecond, and the drive takes some time stepping to the next cylinder (track).
Could one generate magnetic flux with software and a coil, so that a physical floppy drive believed it read a floppy disk, but it wasn't a real disk, but just a coil (or 80 tiny coils, on for each track)
???
Yes, this was a thing back in the day to read flash memory cards in a floppy drive (this product used a single head and special drivers since it needed to support disks bigger than 1.4 MB) https://en.wikipedia.org/wiki/FlashPath
I think it'd be interesting to connect a high sensitivity / resolution sampling probe directly to the analog output of the drive heads. You could do software-defined signal processing to potentially recover damaged data. These USB-based tools are getting the signal after being amplified in the analog domain and processed by the drive's electronics.
The first floppy from 1967 only had one side. Adding one signal to select side was an easy solution to increase the capacity without to much modification of the controller. Adding the capability to read from both heads at the same time would require much more modifications, and more memory.
Undeniably true; so much of computing hardware (and software) looks archaic and bizarre because it's the process of a long chain of backwards compatible changes (don't get me started on ATAPI).
But that aside, like dusted I too wonder just _how_ hard it would have been for a company like, say Apple, to demand the extra circuit. Might not have been worth it for just 2X speedup.
Yeah, but then you need twice the CPU cycles to encode/decode it. And that may have been the limiting factor when first introduced.
After that it’s all backwards compatibility. No one wants a new interface.
I remember the first time I saw a floppy pin out, I was dumbfounded. I expected it to be far more complex like IDE. I didn’t realize the term “floppy controller” would be so literal.
Of course in retrospect it makes sense. IDE = Integrated Drive Electronics. I assume the hard disks that came before worked more like the floppy and their controllers did more work too.
I guess no one cared enough to enhance the poor floppy drive until we got to things like LS-120 that I assume flat out couldn’t use the old interface and never took off anyway.
The ST506 interface between the controller and drive was derived from the Shugart Associates SA1000 interface,[5] which was in turn based upon the floppy disk drive interface,[6] thereby making disk controller design relatively easy
But as they started wanting to make disk reads faster and faster, the drive part had to get smarter and smarter
The ST412 disk drive, among other improvements, added buffered seek capability to the interface. In this mode, the controller can send STEP pulses to the drive as fast as it can receive them, without having to wait for the mechanism to settle. An onboard microprocessor in the drive then moves the mechanism to the desired track as fast as possible
At that point the drive is starting to getting smart enough that you might as well integrate the whole controller on there.
The original versions of IDE/ATA were basically just an extension of ISA, and the first "IDE cards" were just a bridge to the ISA slot they went in.
{kind=link}
Consider what would happen if a data sector contained 12 * 0x00, 3 * 0xA1, 0xFE, ... then this implementation could mis-sync. On real hardware you'd have to be even more unlucky to have the CRC match -- which also isn't checked in this implementation. Using this as-is on real floppies could result in reading corrupt data. It would be possible to construct a floppy that would read correctly on real hardware and sometimes mis-read data with the current SW implementation.
The problem is that the 0xA1 bytes on the disk are special. The 0xA1 bytes are MFM encoded with a missing clock pulse -- making them "0xA1 syncs" that don't match an 0xA1 data byte.
This is what I think dragontamer is alluding to in another thread -- you cannot properly decode the header unless you also recognize the missing clock pulse. So it is important to do the clock recovery in order to notice this.
The special encoding is also present for 5.25 and early hard drives using MFM encodings.