I beg to differ here. Or let's say that the React "functional programming" model has very little to do with the actual functional programming done by actual functional programmers. What is true is that React components are functions. But functional programming and programming with functions are two different things.
Second, side effects are just about in every React component where you use a hook.
Third, (hypothesis) `useEffect` is probably a misnomer that stick there because it would be a breaking change to rename it to something more proper.
Words and bickering aside, you can write great applications with React, that's fact. It is also a fact that a lot of folks are using it wrong, which shows either a problem with React learnability itself, or with its documentation, or well, with the programmers themselves.
> side effects are just about in every React component where you use a hook.
I would expect most of your side effects to happen as a result of user interaction, i.e. in an event handler. Data fetching would probably be at the top of the tree. What side effects are you including in every component?
> a problem with React learnability itself, or with its documentation, or well, with the programmers themselves
All three!
- Most programmers dont learn FP before adopting React, which means they aren't going have a more difficult time working with React's functionalish model.
- Lots of blog posts, tutorials and even docs of popular libraries feature poorly written React code. It's just reality. Lots of people use this library, and there's no barrier to entry to write a tutorial post. IMO, the new React docs are a step in the right direction and should be a primary learning material for most.
Hi there. IMO, there are three issues there: familiarity, mental model, and caveats (using $ and not getting reactive updates in some cases).
Focusing on mental model, maybe my mental model can inspire yours? Here it goes.
- For me, `$: dependent variable = expression(independent variables)`, is an equation that Svelte guarantees will hold across the single-file component (SFC). So whenever an independent variable change, the dependent variable is also updated to maintained the equation.
- Caveat: In the statement `$: dependent variable = expression(independent variables)`, the expression language is JavaScript but the semantics of the statement are Svelte's (i.e. *Svelte's* scoping rules apply, not JavaScript's). SvelteScript is so close from JavaScript that it feels intuitive to use but confusing when the two differ. In a poor analogy, just like using a word that means something in French, another in Spanish, and wrongly guessing the source language (hence the meaning) that applies.
Then:
- `$: {some statements here featuring independent variables}`. *Svelte's* scoping rules apply (only the variables visible in the block are targeted by Svelte's reactivity). This is not an equation anymore, it is the expression of an effect triggered by change in dependent variables.
Why this is natural to me? At the specification level, reactive systems are specified with three core syntactic constructs:
1. event -> reaction
2. dependent variable = function (independent variable)
3. dependent variable <- function (independent variables)
The first item means is where you specify what happens when an event occurs. for instance button click -> (counter <- counter + 1; render new counter)
The second item is the same as lambda abstraction. Say `area = f(length, width)`. That's true all the time and allows using `area` everywhere needed instead of `f(length, width)`. But by referential equality rules, you could absolutely do away with `area` - at the expense of course of less clear and more verbose code (and probably less performant too)
The third item is assignment, and is used to describe changes in the state of the component. As a rule, (reaction, new state) = f(event, current state). So the third item describes how to get new state from current state. The first item describes how to get the reaction from the event and current state. The second item is optional but helps a lot readability, conciseness, and performance (not computing `area` twice if you use it twice).
In Svelte syntax:
1 is $: {reaction code here} (event is some change in value of variables scoped in the code)
1 bis: <some html code here> is the same case as 1 with a different syntax when the reaction is a (re)render. Whenever the dependent variables in scope change, a rerender reaction is executed.
2 is $: x = f(a,b,c,...) (Note that the right hand is a single variable name)
3 is any assignment occurring in the SFC.
Not sure if that helps, but well, that's how I stay away from the pitfalls of mixing SvelteScript and JavaScript. Identify events, state variables, the reaction to the events, and the state changes. Then translate that into SvelteScript.
:-) I feel you. I like to think that state machines are used where they are useful (in some games, process orchestration, generators, embedded systems, etc.). The question is more where else can they be useful given that the low hanging fruits have already been harvested.
So far I have to say that it is a mixed experience. There is a cost to the abstraction and the indirection (that is fairly well known easy to describe even if we rarely do so due to some self-imposed no-negativity bias or having some interest in the game), and then there are the benefits that are less easy to describe because they depend highly on the nature of the problem that you are addressing.
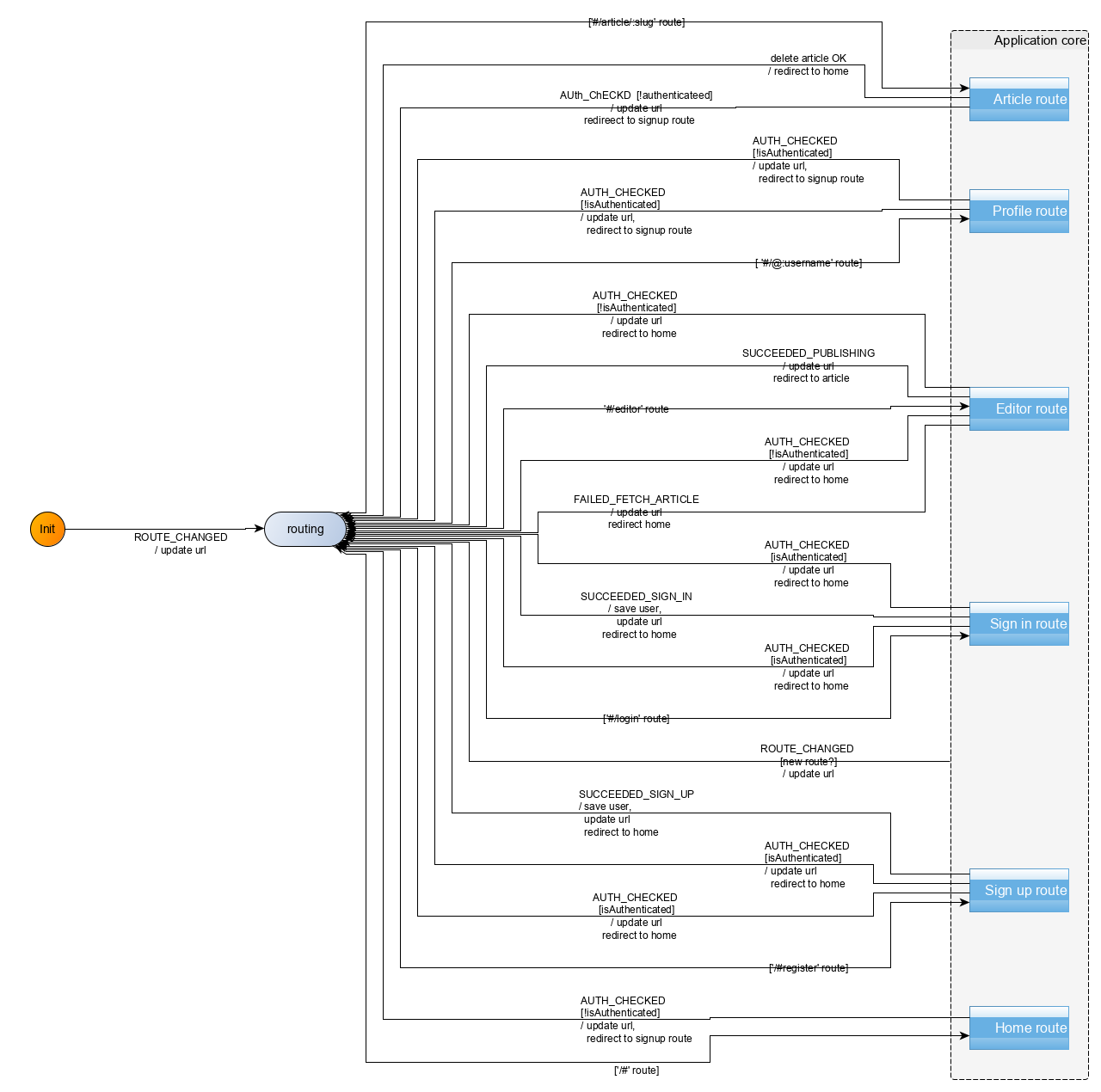
I implemented a Medium clone application (https://codebase.show/projects/realworld) with state machines. The result is 47Kb (brought down to 39Kb after compiling the machine and other optimizations) vs. 70Kb for the Vue implementation or 160 KB for the React/Redux one (that implementation piles abstraction over abstraction in the form of libraries and pays the corresponding price). I would count that as benefit. Also cf. https://brucou.github.io/documentation/v1/tutorials/index.ht... for the full pitch.
At this level, you can follow the routing of the app. Every route is a compound state. If you open it, you see the details of the behavior. The full machine (post refactoring) is like this: https://brucou.github.io/documentation/graphs/real-world/rea...
So one advantage is that with those graphs, it is easier to onboard new folks arriving to the codebase. They just have to follow arrows to know what the code is doing in response to a series of inputs.
I could continue but with all that said, the Hyperapp implementation of the same application is 27Kb and also fairly simple (even if arguably not as simple) to get into. So there isn't a clear-cut ex-nihilo benefits to state machines here. In fact if you would have implemented the same application as a MPA instead of a SPA, for most, if not all of the pages, using a state machine to model the behavior is simply overkill. Most of the job and value of the machine in my example is to do the client-side routing done in the machine (so no extra library cost).
Anyways the bottom line is the tool is useful but you have to figure for what, and where is the value maximized. The obvious cases have already been figured out.
If we talk about professional use, then Powerpoint (many years ago), then Visio (also many years ago), then yEd (by yWorks, https://www.yworks.com/products/yed). Then there are a ton of specialized open-source tools, with varying quality. Mermaid improved a lot. PlantUML has a lot of options, but I would not use it professionally. draw.io has also plenty of options, but has some usability issues in the frame of a frequent, professional use.
For anything UML-related, Enterprise Architect is quite good, but boy you better know UML. That ain't user-friendly in the least. But super powerful and there are a few more like that out there with somewhat limited free versions.
Long story short, my best choice is yEd. And I still reach out to Powerpoint every now and then.
I do agree with the thesis that nobody got fired for using React. I don't however think that the conclusion is to use React anywhere for anything.
From what I read here, what happened here is that this developer has good knowledge of React for having used it repeteadly in the past. At the same time, he did not have experience in lit or svelte. He hit some issues and then went back to the things he knows better. It is more comfortable and more productive, there is no doubt about that. The conclusion is more like, you will write your app faster in the language, environment, and framework that you already master. I agree with that. Change one of those, and you will go through some moments of loneliness. Change two of those, you may just fail the project entirely.
What is true, and proven by many data points, is that you can write complex applications with lit-html, svelte, elm or just vanilla-JS. GitHub is not a web graphics editor but it is entirely vanilla JS. Hum, po*n apparently use plenty of vanilla JS too (https://davidwalsh.name/pornhub-interview). IBM implemented their Carbon design system in Svelte. Adobe's adaptive color tool (https://leonardocolor.io/?colorKeys=%236fa7ff&base=ffffff&ra...) is entirely in vanilla-JS. The list is long.
So what we have here is one anecdote from one person. All data points issued from real experience are welcome, valid and useful but we should be careful to not get to conclusions too fast.
I outline in a ~20 page whitepaper why Mithril for JavaScript/TypeScript UIs (plus Tachyons for Atomic CSS) is a better choice over React and Angular for Single-Page Applications based on experience with all three: https://github.com/pdfernhout/choose-mithril
"tl;dr: Choose Mithril whenever you can for JavaScript UI development because Mithril is overall easier to use, understand, debug, refactor, and maintain than most other JavaScript-based UI systems. That ease of use is due to Mithril's design emphasis on appropriate simplicity – including by leveraging the power of JavaScript to define UIs instead of using an adhoc templating system. Mithril helps you focus on the essential complexity of UI development instead of making you struggle with the accidental complexity introduced by problematically-designed tools. Many popular tools emphasize ease-of-use through looking familiar in a few narrow situations instead of emphasizing overall end-to-end simplicity which -- after a short learning curve for Mithril -- leads to greater overall ease-of-use in most situations. ..."
Two key points there are that React's setState(..) approach to minimize redrawing is a premature optimization (which then leads to wastelands of endless opaque boilerplate like Redux) -- and also JSX is completely unnecessary and counter-productive compared to just using HyperScript API to define interfaces in plain JavaScript/TypeScript without needing to introduce extra compilation steps or more complex tooling. Another key point is that Atomic CSS like Tachyons and similar approaches obviates the need for all kinds of specialized CSS encapsulation complexity. Mithril and Tachyons leverage the flexibility of HTML, JavaScript, and CSS without trying to reinvent too many other complex layers above them -- layers which typically just create more problems in the end via accidental complexity unrelated to actually creating UIs.
In general that analysis applies to most current JavaScript-based UI libraries. Elm (which perhaps helped inspire Mithril as a vdom) or ClojureScript or other similar tools might be exceptions though for people willing to put the time into learning those languages (which compile to JavaScript) and dealing with integration issues.
So, in reading the article and also much discussion here and elsewhere, much of that verbage to my mind fits into the category of seeing (yet again) inexperienced or otherwise constrained developers picking one problematical tool and struggling with it and then jumping to another one with different (perhaps lesser) issues again without having broadly surveyed what is out there or understanding key concerns like simplicity. Of course what is much more painful is working in organizations where such faddish choices are then forced on developers who know better (as is often the case, including sadly why I know so much about Angular and React even after years of experience using Mithril successfully).
That said, once a critical amount of time and money has been spend in getting developers to use a particular solution like React, then yes, there is the sunk cost which makes it easier for an organization to do other projects in it and maintain them. Just like why a lot of other legacy software persists...
Just like Facebook could promote React aggressively over alternatives (even when React had the problematical patents clause in its license), I'm reminded a bit of when Java overtook Smalltalk in part due to huge amounts of money pumped into advertising and promoting it (including by IBM, which ironically eventually had two good Smalltalks of its own).
Every tool has its strengths and weaknesses in different situations (including Mithril and Tachyons). And I can accept that broad industry adoption is a plus for any tool for availability of developers and third-party libraries. Still, it's sad for me -- after having implemented UIs for about four decades in hundreds of different ways -- that when I find something like Mithril that works really well for current needs and has (all things considered) great developer ergonomics and a great (if small) supporting community, it is mostly ignored. While Mithril+Tachyons+ES7 works differently than Smalltalk and related UI libraries, that combination makes UI development almost as fun as it was in Smalltalk -- but with broader reach because HTML+CSS+JavaScript is now everywhere. For good or bad, I guess Mithril will remain a "secret weapon" like Smalltalk used to be. :-)
State machines are a generic term. You will find here the different kinds of state machines, with varying expressive power that are used in computer science and actuak programming: https://github.com/achou11/state-machines
In any case, keep in mind that Turing machines are (extended) state machines (albeit with infinite memory) so the expressive power of state machine is at least anything computable (sequentially - turing machine is a model of sequential computation).
I have been looking for that too and could not find much, at least not much that is available for free. That said, I give a series of example of miscellaneous complexity in Kingly documentation site (https://brucou.github.io/documentation/). Kingly is a state machine library that replicates pretty much the formalism of statechart, without its concurrency model (i.e. no parallel states). Interestingly the amazon book you quote is also recommending to make spare use of parallel states (if I remember well, it recommends to use it only at the top-level of the chart, and when possible not at all).
Anyways, on the Kingly site, you will find the following examples:
- a counter (yeah there is always a counter or hello world somewhere)
- a keypad app (with Svelte)
- a password meter (tells you if yuor password is strong enough)
- a two-player chess game (with React)
- an interface to an online movie database (with 7 different UI libraries, including Vue, React, Svelte, Ivi)
- a wizard form (with cycle.js)
- an implementation of suspense functionality (with Svelte)
- an implementation of Conduit, a clone of Medium. Conduit is considered to be, like TodoMVC a benchmark of miscellaneous approaches to UI implementation, but for a real world complex application.
All of that may be useful to you, with the benefits that you won't have to make the examples, as I had to, to evaluate the applicability of the technique to UI implementation.
If there is anythign you do not understand let me know.
That is one of the early papers by David Harel which divulgated statecharts among the scientific community. Note that since then, there has been a number of criticisms made about the original statecharts (namely the absence of precise semantics, and the concurrency model) and a number of variants have since seen the day. What seems to have remained in all variants is the concept of hierarchy. In the Kingly state machine library (https://github.com/brucou/kingly), I only use hierarchy and discard broadcast and concurrency. The latter two can be added at will according to the problem at hand.
I find your thesis interesting (that agile ended the top-down design approach resulting from statecharts modeling). Do you have any references/links I can review to support it? It is true that agile seems antithetic to Big Design Up Front (http://www.agilemodeling.com/essays/bmuf.htm). However the methods did seem to have found commercial success (in safety-critical software) albeit not in front-end programming.
I believe instead that the drivers of adoption/rejection are specific to the success factors in specific industries. That or maybe front-end programming is driven more by trial and error (+ hype?) than by engineering.
In conjunction with predicates, which tell you which edge you can explore, and when to stop a path search (a test sequence is a path), this gives a pretty flexible and configurable tool for automatic test generation, as you observed.
So far I preconfigured two search strategies, one which visits all transitions in the graph once, and the second which does the same but up to n visits of the same transition. I am working on more complex strategies (favor some paths over some others following a probability distribution etc.) but that is not a priority as of now.
Smart automated test generation is an exciting topic!
{kind=link}
{kind=link}
Second, side effects are just about in every React component where you use a hook.
Third, (hypothesis) `useEffect` is probably a misnomer that stick there because it would be a breaking change to rename it to something more proper.
Words and bickering aside, you can write great applications with React, that's fact. It is also a fact that a lot of folks are using it wrong, which shows either a problem with React learnability itself, or with its documentation, or well, with the programmers themselves.