Spoken language descriptions of how to do something are incredibly underdetermined. Many people are likely familiar with the meme of following exact instructions on making a PB&J where a phrase like “put a knife in your hand and spread the peanut butter” can result in stabbing yourself and rubbing peanut butter on the wound. More than half of my job is helping other people know or otherwise determining what they really want a program to do in the first place.
Ethics of Chinese vs. Western companies? Everything. I'm sure you're aware of how many hundreds of $billions of American IP are stolen by Chinese companies.
With completed legal proceedings, at least two cases: Xiaolang Zhang was sentenced in 2024 for stealing Apple's AI autonomous vehicle tech for Chinese AI company XPeng. Xiang Haitao was sentenced in 2022 for stealing Monsanto's AI predictive algorithm for a Chinese research institute.
> It does 100 interviews, and it’s going to hand back the best 10 to the hiring manager, and then the human takes over,” he says.
Yikes. One thing that's incredibly important about reaching the interview-stage of a job application has been that there is a parity, or even an imbalance favoring the candidate, in human time usage. The company's people (often multiple people at once) have to spend time with the candidate to conduct the interview, so there are stakes for scheduling an interview. The company is investing something into that interaction, so you as a candidate can have some faith that your time is being valued. In the very least, your 45 minute interview is valued at 45*n minutes of company labor for each interviewer.
Admitting right off the bat that you're going to waste the time of 90% of your applicants without these stakes is just wildly disrespectful.
> Admitting right off the bat that you're going to waste the time of 90% of your applicants without these stakes is just wildly disrespectful.
They were already doing this. Now it is just more automated. You didnt have the right keywords. 2pts into the basket. Too long (meaning old/bad team fit), gone. You worked for a company that might have some sort of backend NDA, gone. Wrong school, gone. Wrong whatever, gone. You were never getting to the interviewer in the first place. You were already filtered.
The reality is if they have 1 position open. They get 300 resumes. 299 of them need to go away. It has been like this forever. That AI is doing it does not change anything really. Getting anyone to just talk to you has been hard for a long time already. With AI it is now even worse.
Had one dude who made a mistake and closed out one of my applications once. 2 years after I summited it. Couldn't resist not sending a to the second number days/hours/mins how long it took them. Usually they just ghost you. I seriously doubt the sat for 2 years wondering if they should talk to me. I was already filtered 2 years earlier.
> They get 300 resumes. 299 of them need to go away. It has been like this forever. That AI is doing it does not change anything really.
That's not really true.
From the candidate, there's the effort to submit a resume (low), and then the effort to personally get on a video call and spend 45 minutes talking (high).
Discarding 290 out of the 300 resumes without talking to the candidate is way more acceptable, because the effort required from the company is about the same as the effort required by the candidate.
Asking the candidate to do an interview with an AI flips this; the company can en masse require high effort from the candidate without matching it.
> Asking the candidate to do an interview with an AI flips this; the company can en masse require high effort from the candidate without matching it.
I don't disagree. These systems are already awful to get into. Some have dozens of pages you have to fill in for your 'resume'. Just for at the end to ask for docx file of your resume. So we probably will get that PLUS this AI stuff (you know just in case /s).
It is what it is. But surely the difference here, and a pretty galling difference, is that the 299 candidates are now “wasting” double the amount of time than pre-ai times. Time spent doing the traditional application process + now an additional time talking to a bot to simply get to the same dead end
> They get 300 resumes. 299 of them need to go away. It has been like this forever.
I doubt that. The number of applicants per job has gone up over the past few decades. Likewise, the number of jobs that people apply to has gone up too.
But see the other end of the exchange. This is going to allow filtering out people that had no business applying in the first place yet increase the resume noise for the rest of us. For the good role candidates it sounds like this may increase your success rate.
I.e. if 1000 applications get 10 human interviews before, your chances of being picked are minimal, but if 100 get ai interviews, you have a bigger chance of standing out in the sea of fake resumes.
1. An Ai can truly find the best candidate (spoilers: the best candidate is not one who spouts out the most buzzwords)
2. The Ai will not profile based on illegal factors, given that many of these interviews insist on a camera (even pre-llm there are many biases on everything from voice assistants to camera filters to seat belt design).
3. That humans will spend anytime refining andnirerwting an AI to improve beyond hitting those 2 factors, among many others. What's the incentive if they are fine automating out the most important part of a company's lifeblood as is.
Maybe I am doing it wrong as an Engineering Director, but technical round 2's are with me for 90 minutes. I often explicitly tell the candidate that I respect their time and that is why they are getting 90 minutes of mine, and not a take home. It is exhausting, but we have gotten some excellent hires this way.
Well, I suppose same way you reduce spam and abuse anywhere else.
Raise the cost enough it's not worth it. Some middle ground could be requiring mailed in applications. That's a marginal cost for a real applicant but a higher cost for someone trying to send swathes of applications out.
It might seem backwards but there are plenty of solid non technical solutions to problems.
You could also do automated reputation checks where a system vets a candidate based on personal information to determine if they are real but doesn't reveal this information in the interview process.
That's how all government things tend to work (identity verification)
The people are usually real in my experience, although I’ve dealt with fake people a few times. Different person showing up to the office vs the video interview, man obviously just off camera giving answers. That second one is probably AI now.
HR attempts to prescreen on resume match. I’ll never see the person who matches on half the skills and is a real person. I’ll only see the fraud until I accidentally find someone who has ever used the technologies on their resume.
if AI could really one-shot important, interesting apps, shouldn’t we be seeing them everywhere? where’s the surge of new apps that are so trivial to make? who’s hiding all this incredible innovation that can be so easily generated?
If AI could really accelerate or even take over the majority of work on an established codebase, we should be seeing a revolution in FOSS libraries and ecosystems. The gap has been noted many times, but so far all anyone's been able to dig up are one-off, laboriously-tended-to pull requests. No libraries or other projects with any actual downstream users.
But plenty of maintainers are in the business of spending mass amounts of time, energy, and actual money on open source projects. Some make a business out of it. Some are sponsored by their employer to spend paid work hours on FOSS projects. If LLMs could help them, some significant number would.
But if there are any instances of this, I have not seen them, and seemingly neither has anyone I've posed the question to, or any passersby.
Somebody would. Somebody would be an AI evangelist, or would become one. The FOSS ecosystem is large enough to be sure of that. We're not seeing nothing, we're just not seeing at all what the marketers and AInfluencers are prophesying. We're not even seeing what you describe. Why is that? Why is it limited to random commenters and not seen at all in the wild?
There is a Cloudflare project that published the entire AI generated history complete with prompts. And of course in many projects the majority of PRs are opened by dependabot, it's not an LLM but it's a "bot" at least.
I agree we're not seeing open source projects be entirely automated with LLMs yet. People still have to find issues, generate PRs (even if mostly automatic), open them, respond to comments, etc. It takes time and energy.
I've made another comment in this thread about a nice tool I one-shotted. The reason I don't publish anything now is because in the UK at least, companies are not behaving will with relation to IP: many contracts specify that anything you work on that can be expected of you in the course of your duties belongs to the company, and tribunals have upheld this.
There's also a bit of a stigma about vibe coding: career wise, personally I worry that sharing some of this work will diminish how people view me as an engineer. Who'd take the risk if there might be a naysayer on some future interview panel who will see CLAUDE.md in a repo of yours and assume you're incompetent or feckless?
Plus, worries about code: being an author gives you a much higher level of control than being an author-reviewer. To err as a writer is human, to err as a reader has bigger consequences.
Well no, not really. I’m replying in the context of the parent comment, that was painting a scenario where the GPT would reply with information relevant to different countries.
It doesn’t need to be advanced prompting, it’s enough to provide enough information and ask to “provide advice relevant to the current and applicable codes and regulations”
It’s the first question a forum dweller would reply to a poorly articulated post.
And how would the LLM know that a comment in english in a random forum is applicable to a specific country but not another?
UK, US, Australia all have different rules and regulations, but their websites don't exactly advertise their location. It is implied that you visit them based on your country. The UK has a weird mix of metric and imperial, so you can't even use the units to figure it out!! It's not always easy to figure it out, even for a human.
I think you're exaggerating. There are several ways an LLM can discern the applicability of certain data to a context (document metadata such as TLD, cross check with applicable authoritative codes and regulations, be wary of random forum posts.)
I'm pretty sure an LLM can provide pretty refined answers given some reasonable context. i.e. I want to rewire a socked in my apartment, which is in London, UK. What do I need to do?
Because they may change their plans. They could be a no-show (which will affect your return flight). They could call and change the flight without your knowledge. They could add extras to the trip and charge it to your card.
People are flaky, and being on the same itinerary with the same PNR as someone else means your trip is in their hands.
Some sort of service that sat on top of bookings would have its own set of terms and conditions that you agree to, which would at least disincentivize them from acting against your interest.
Yes, there's a podcast with the post-training lead for L3 where he mentions this. Lemme try and find it.
edit: found it. The money quote is here, but I really recommend the entire podcast since it's full of great tidbits and insights.
> Thomas [00:33:44]: You mean between supervised fine-tuning like supervised fine-tuning annotation and preference annotation? Yeah. So 100% to RLHF. In fact, that's quite interesting. You start for Llama 2 with a pre-trained model and you have to have an instruction model to chat model. Otherwise, like the model is just like continue finishing sentences. So you need that to start RLHF. So we had to annotate like 10,000 examples. What did we do for Llama 3? You start with a new pre-trained model and then you want, before starting the RLHF, to have now a chat model, which is not too bad. The option one was, let's do human annotation again, like SFT stage. But in fact, by the principle I said before, the annotation would be actually worse than Llama 2. So what we did is that we generated all the data on the prompts with Llama 2 and we applied like basically the last round of Llama 2 we had to kick off and start Llama 3 post-training. So Llama 3 post-training doesn't have any like human written answers there basically, almost. It's just leveraging pure synthetic data from Llama 2.
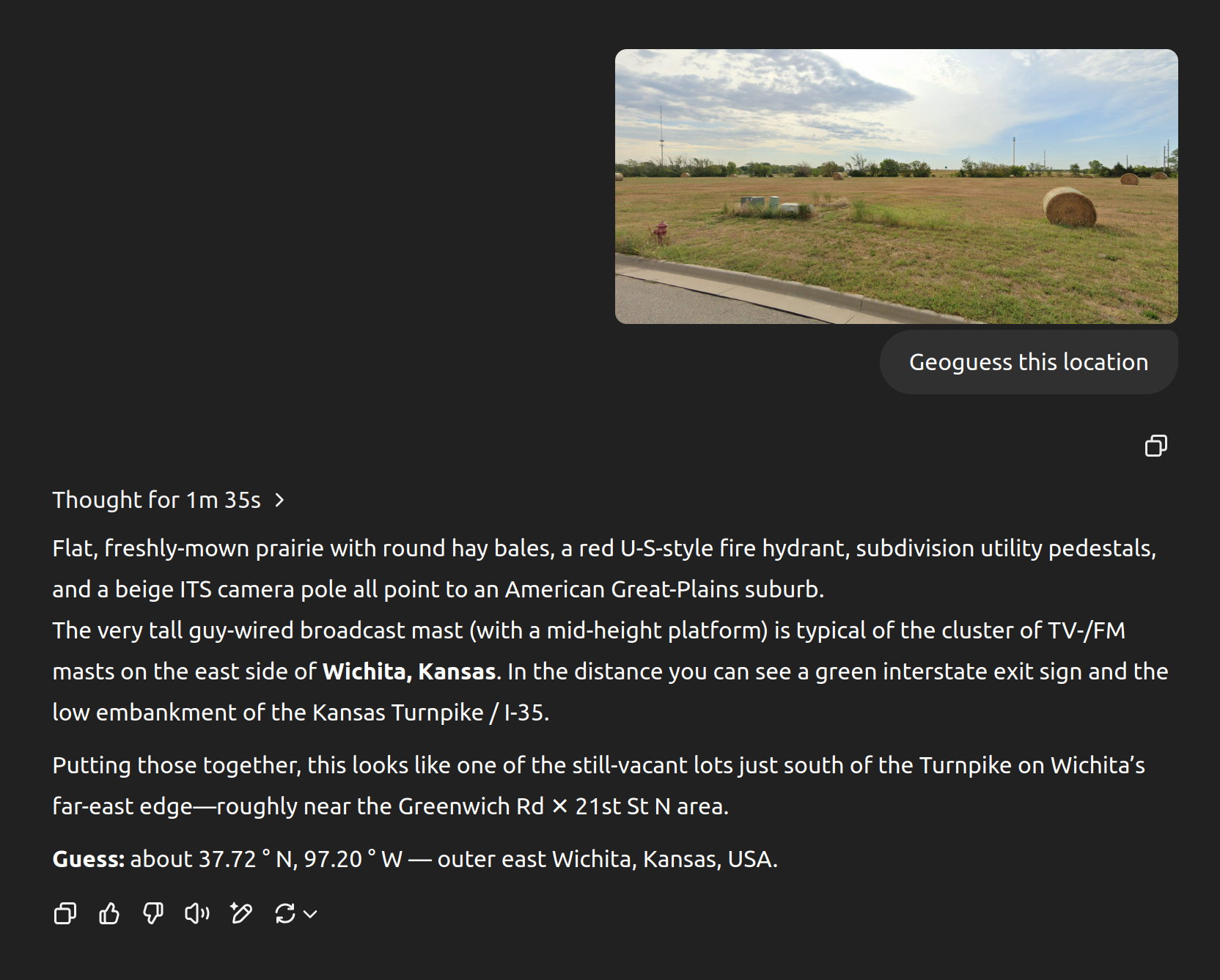
Your skepticism is warranted though - I was a part of an AI safety fellowship last year and our project was creating a benchmark for how good AI models are at geolocation from images. [This is where my Geoguessr obsession started!]
Our first run showed results that seemed way too good; even the bad open source models were nailing some difficult locations, and at small resolutions too.
It turned out that the pipeline we were using to get images was including location data in the filename, and the models were using that information. Oops.
The models have improved very quickly since then. I assume the added reasoning is a major factor.
There's no metadata there, and the reasoning it outputs makes perfect sense. I have no doubt it'll be tricky when it can be, but I can't see a way for it to cheat here.
This is right by where I grew up and the broadcast tower and turnpike sign were the first two things I noticed too, but the ability to realize it was the East side instead of the West side because the tower platforms are lower is impressive.
One glaring defect in our collective ability to think critically about blockchain is that many have invested in it, making it extremely difficult to be objective.
{kind=link}
{kind=link}