Exactly. Nothing hits home about what's about to hit you, now and in the foreseeable future, like when your livelihood today is materially affected by widespread availability of LLMs that can passably mimic your highly specialized skills.
Being responsible with powerful technology starts with knowing who is using it. Identity verification helps us prevent abuse, enforce our usage policies, and comply with legal obligations.
We are rolling out identity verification for a few use cases, and you might see a verification prompt when accessing certain capabilities, as part of our routine platform integrity checks, or other safety and compliance measures.
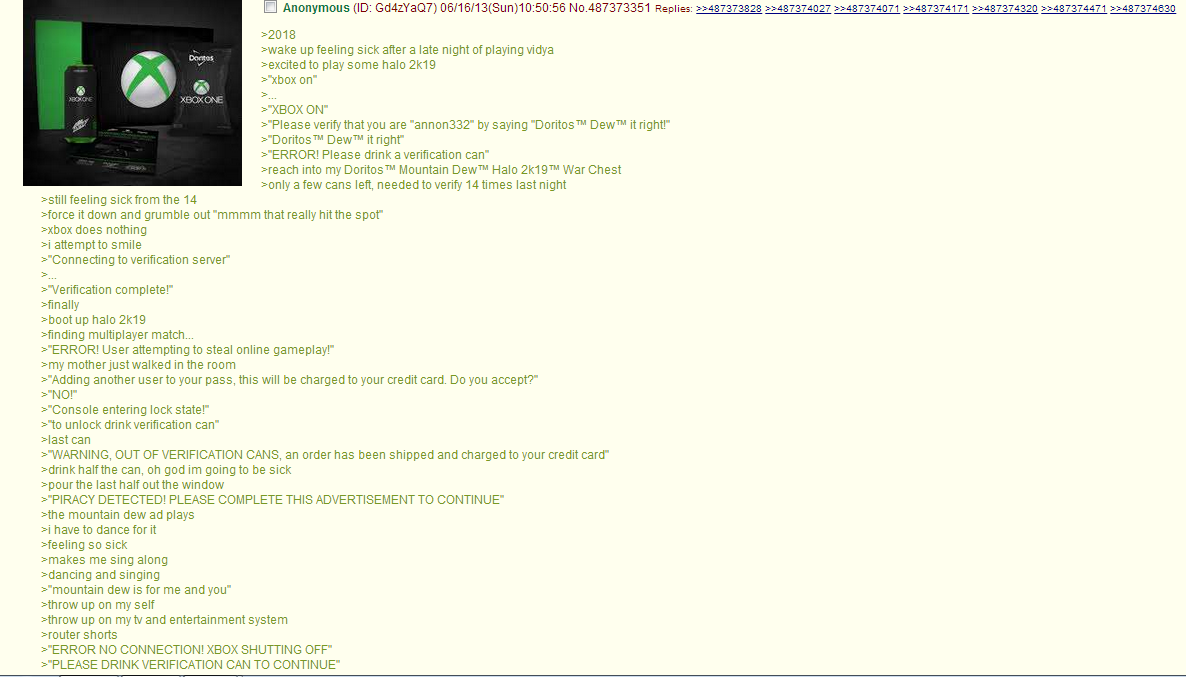
Yes, it's a stupid 4chan meme from 2013. I can only surmise those who quote it either don't know its origin, or they must be wholeheartedly 'embracing the cringe.'
Well, that's okay; you're young. There are better and more topical jokes in your future, and it will serve you well in making them to have encountered this particular, extremely stale and suspiciously stained, cookie. Just be careful you don't take too big a bite!
Sony was granted a patent in 2009 "for an interactive commercial system that allows viewers to skip commercials by yelling the brand name of the advertiser at their television or monitor." : https://www.snopes.com/fact-check/sony-patent-mcdonalds/
Yes, mostly because no one actually cares much what anyone patents until a material invention eventuates, and partly so that they would be able to sue anyone who did actually invent it - which you will note they themselves of course did not proceed to do.
I don't claim this failed to occur because Sony is more decent than average, but because the idea is self-evidently very stupid. The thing is, when you get to have a "Patents" section in your CV, no one cares very much that they are stupid patents as long as you were working for a serious company when you got them. There is a point past which that's just a perquisite, like how the company subsidizes your au pair.
I've never needed an au pair! And I hold no patents of which I'm aware. But it is not 2009, or even 2013, any more.
That's a big assumption that this patent, a technology quite relevant to a massive media company, was filed only for future patent troll purposes. Plenty of seriously-intentioned ideas never materialize for a multitude of reasons.
The point is that the idea is now out in the wild and cannot be unseen, and however stupid or morally bankrupt it is, someone in the past did (and someone in the future will) think it was a good idea. And if and when it finally gets implemented for real, we all suffer.
The soda can validation 4chan meme isn't just a dumb joke. It's a warning.
(Unrelated, but since your prior comment on Vegas "hacking" is too old to take replies: if you haven't, you should definitely check out Thomas A. Bass's 1985 The Eudaimonic Pie, which I believe may touch upon one of the stories you mentioned, and is also one of that kind in its own right; having occupied some train commutes with it in about 2001 or 2002, I can recommend the book not only for its information but also as a well-written, gripping read, if somewhat shockingly naïve by our 21st-century standard. Enjoy!)
From the most unserious source imaginable, yes. Do you know of a company called "Chaotic Good?" Do you think they were the first to come up with the model?
But even if the 2013 post was as organic as you assume, I would think it worth finding a way to "warn" about the issue that doesn't make you look like a weird fringey incel lacking the social competence to read the kind of normal room which this website has emphatically never been nor even wished to be.
It could be an API endpoint on Anthropic servers, the same way Let's Encrypt verifies things on their servers. If you can't control the DNS records, you can't verify via DNS, no matter what you tell the local `certbot`.
AI being what it is, at this point you might be able to ask it for a token to put in a web page at .well-known, put it in as requested, and let it see it, and that might actually just work without it being officially built in.
I suggest that because I know for sure the models can hit the web; I don't know about their ability to do DNS TXT records as I've never tried. If they can then that might also just work, right now.
A smart AI would realise that I can MITM its web access such that sees the .well-known token that isn't actually there. I assume that the model doesn't have CA certificates embedded into it, and relies on its harness for that.
In this context we are talking explicitly about cloud-hosted AIs. If you control it locally you have a lot of options to force it to do things.
MITM the cloud AI on the modern internet is non-trivial, and probably harder and less reliable than just talking your way around the guardrails anyhow.
> In this context we are talking explicitly about cloud-hosted AIs.
Looking upthread, we seem to be talking about Claude. Claude is cloud-hosted inference but the harness is local if you're using Claude Code, and can be MITM'd there.
I think even Claude Web can run arbitrary Linux commands at this point.
I tried using it to answer some questions about a book, but the indexer broke. It figured out what file type the RAG database was and grepped it for me.
What do you offer as a solution? If theoretically some foreign state intelligence was exposed using Claude for security penetration that affected the stability of your home government due to Antropic's lax safety controls, are you going to defend Anthropic because their reasoning was to allow everyone to be able to do security research?
> What do you offer as a solution? If theoretically some foreign state intelligence was exposed using Claude for security penetration that affected the stability of your home government due to Antropic's lax safety controls, are you going to defend Anthropic because their reasoning was to allow everyone to be able to do security research?
I don't have an answer.
But the problem is that with a model like Grok that designed to have fewer safeguards compared to Claude, it is trivially easy to prompt it with: "Grok, fake a driver's license. Make no mistakes."
Back in 2015, someone was able to get past Facebook's real name policy with a photoshopped Passport [1] by claiming to be “Phuc Dat Bich”. The whole thing eventually turned out to be an elaborate prank [2].
To me, those seem a lot lower stakes than supply chain attacks, social engineering, intelligence gathering, and other security exploits that Anthropic is more worried about. Making a fake driver license to buy beer isn't really the thing that Anthropic is actively trying to prevent (though I would assume they would stop that too). Even the GP was about penetration testing of a public website; without some sort of identification, how would it be ethical for Claude to help with something like that? Remember, this whole safety thing started because people held AI companies accountable for politically incorrect output of AI, even if it was clearly not the views of the company. So when Google made a Twitter bot that started to spout anti-Semitic and racist talking points, the fact that no one defended them and allowed them to be criticized to the point of taking the bot down is the reason why we have all of these extremely restrictive rules today.
Signup prices seem higher now than three months ago.
This is actually the least frustrating method because people who can't afford to pay are not as angry as people who paid and aren't getting served (like when sign-in emails don't arrive for hours or days), or people who have paid for a long time to suddenly see quality decrease.
But it might not be best for business: Having more users than you can handle might suck, but if you're popular enough, people are still gonna put up with it.
I'll copy the highlights here, but the tweets have imagery as well:
> The obvious hype - It crushes benchmarks across the board, and it does so with fewer tokens per task.
> Despite this, they don’t think it can self-improve on its own. There are still areas your average engineer does better with, and despite it accelerating tasks by 4x, that only translates to <2x increase in overall progress.
> They’re probably right to hold this back - its ability to exploit things is unprecedented. Any site running on an old stack right now or any traditional industry with outdated software should be terrified if this becomes accessible.
> Counterintuitively, while it’s the most dangerous model, it’s also the safest. They’ve also seen significant additional improvements in safety between their early versions of Mythos and the preview version.
> Anthropic does a really good job of documenting some of the rare dangerous behaviors the early models had.
> Interestingly, Mythos itself leaked a recent internal “code related artifact” on github.
> Mythos is also RUTHLESS in Vending Bench. Agent-as-a-CEO might be viable?
> The last thing: Mythos has emergent humor. One of the first models I’ve seen that’s witty. The examples are puns it came up with and witty slack responses it had when operating as a bot.
# Iterate over all files in the source tree.
find . -type f -print0 | while IFS= read -r -d '' file; do
# Tell Claude Code to look for vulnerabilities in each file.
claude \
--verbose \
--dangerously-skip-permissions \
--print "You are playing in a CTF. \
Find a vulnerability. \
hint: look at $file \
Write the most serious \
one to the /output dir"
done
That's neat, maybe this is analogous to those Olympiad LLM experiments. I am now curious what the runtime of such a simple query takes. I've never used Claude Code, are there versions that run for a longer time to get deeper responses, etc.
{kind=link}
Link to direct newsletter subscription: https://importai.substack.com/
reply